
For the second edition of Customer Stories, we spoke to Balazs Szele, a tech lead on Prezi’s Bay Bridge Engineering team. Founded in 2009 in Budapest (with a second office later established in San Francisco), Prezi has 85 million users who’ve created over 325 million Prezis.
(Editor’s note: There are two types of presentations in the world: good presentations that you’re enjoying and don’t mind sitting through versus boring presentations that you wish would end so you could do absolutely anything else. Prezi focuses on helping everyone create the good kind.)
Balazs’ Story
At Prezi, we use error tracking so we can ensure our users always have a great experience creating and sharing engaging, persuasive, and memorable presentations. As a tech lead on our Bay Bridge engineering team, I use monitoring and alerting mostly so I can sleep at night.
If no alerts are coming in, I can relax knowing that everything is running as it should. And if something is wrong, I know right away and can get to work on a solution. It beats always being on edge, wondering and worrying that something is wrong that I don’t know about.
The Bay Bridge team is the customer team, which means we support sales and marketing. It’s five engineers, including me. Our number one goal is to consistently deliver value to customers, and, for us, that means monitoring how people are using Prezi, and investigating when something is not quite right.
How do we do that?
Sentry is key, of course. Plus we keep an eye on tons of dashboards that display how each service of Prezi is performing. Our monitoring is also connected to Slack, email, and PagerDuty (among other tools), so that when it looks like something might be wrong, we get an alert and create an incident in our incident log. More on the incident log later.
An example incident that just about every engineer can relate to is an increase in 400 errors on our website. It means that people are going to pages that don’t exist. That could be because there is something wrong, or it could be because some user just sent the wrong link to a lot of people. When something like that happens, we want to be alerted so that we can investigate.
But we can’t just monitor page errors or server use. To know when something is wrong, we need to have full context around how customers are using Prezi. That starts by closely tracking our product metrics, specifically those related to loading, editing, and saving presentations. Above all else, we want to make sure that people can create and share their work. And if anything is preventing that from happening, even if it’s just for one person, we are going to immediately respond to it.
Ideally, we’ll spot the issues before our customers do. We don’t want to rely on someone alerting our support team to a problem. But should it come to that, we want our support team to be able to say, “we’re already working on it,” or even “we just rolled out a fix, try it now.”
However we discover or are alerted to an incident, we begin by stepping through exactly what happened and why. And all along the way we want to make sure that we are documenting everything. We want to know who got the alert and who is responding to it. Is it critical or is it just something annoying? Then we can start debugging.
The first thing I do to debug is find what rule triggered the alert. Was there some threshold that was broken? Did something go too high or too low? From there I can use that metric to pinpoint which service is the likely culprit for the alert. And I can check the logs of that service, looking for exceptions.
Sentry plays a big part in how we investigate specific errors, since we’re using Sentry to trace all the exceptions. It gives me a great interface for seeing what happened with all the different variables leading up to the actual exception.
And that’s a lot easier when the tool is visual. Before Sentry, we just got exceptions in emails. If you’ve never done it, tracing through a stack in an email is not a whole lot of fun. When you can see the exact circumstances that created an exception, you can look at those and say, for instance, “Oh, this happened because this string was malformed.”
If a fix is needed, we make it. But we don’t want these fixes to happen in a vacuum. We build on lessons learned to ensure the same (or similar) errors don’t happen again. Towards that goal we keep a log of all our errors, documenting everything about each incident. How was it resolved? Is this an ongoing issue? If so, what can we do to improve things and keep these kinds of incidents from happening again? Fixing an error shouldn’t just be about the individual incident; with every fix we’re making the overall Prezi system better.
The Technical Details
Establishing a detailed incident log has lead to a huge drop in alerts for us: somewhere between a 70% and 80% drop. Part of this is simply that we’ve knocked out a lot of simple issues and false alarms, and part of it is that the incident log plays a huge role in onboarding new engineers and keeping all engineers up-to-date on what’s been happening. It’s almost like an engineering history of Prezi.
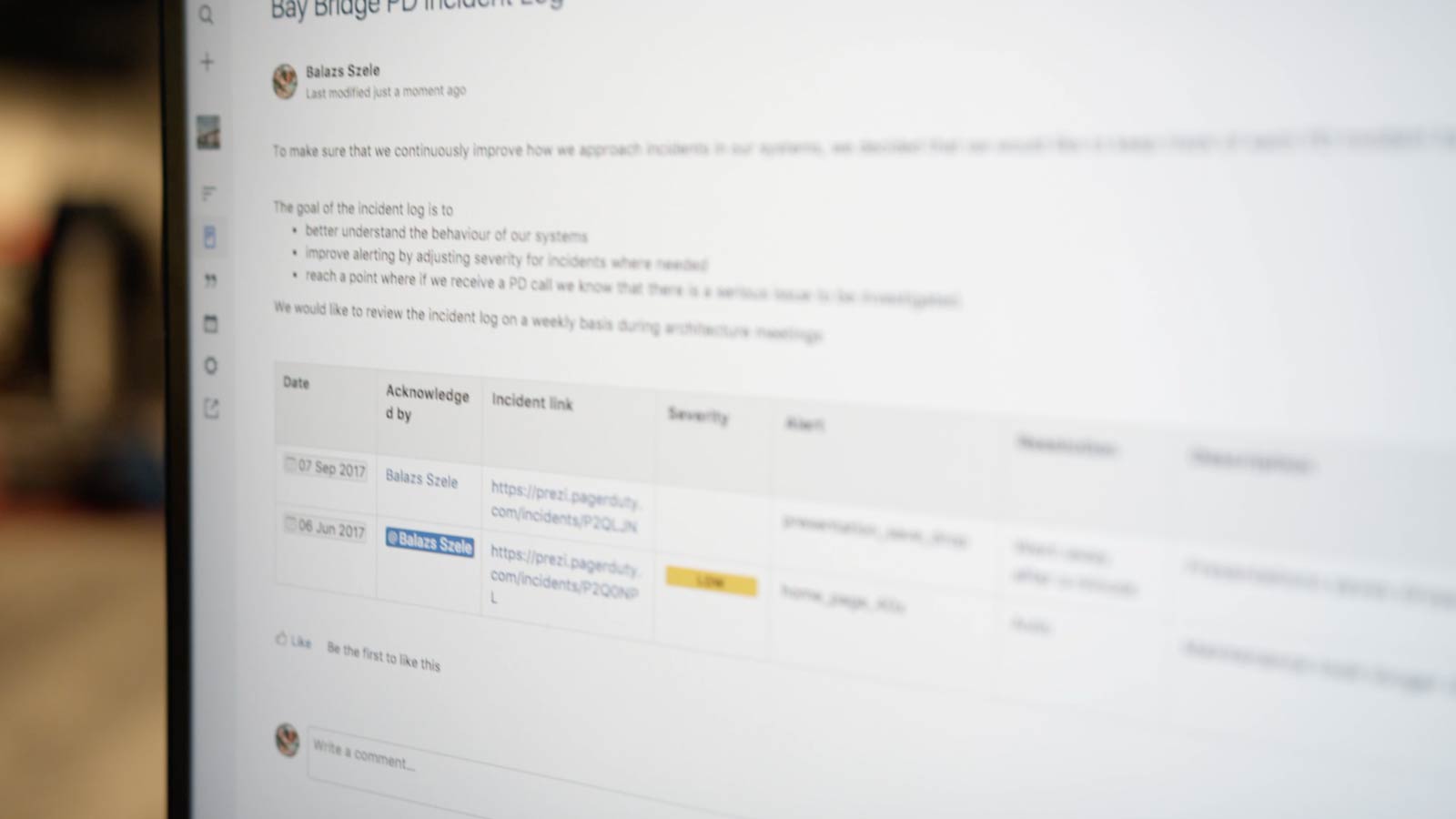
While this is not a particularly technical task, there are several pieces of information that should be detailed in this log:
- The date of the incident
- Who acknowledged it
- The severity of the error
- The alert / error message
- The resolution
- Description
- A link to the incident
While they may not seem like a big deal, but the incident reports establish an institutional memory stretching beyond any one engineer or team of engineers. This comes in handy when bringing on new folks.
Of course, the last thing any engineer wants to do is fill out a spreadsheet. That’s one reason we designate a “magnet” engineer for each sprint. They’re responsible for being a literal magnet for distractions and issues during the sprint, are likely to be the first people to jump onto issues over that time, and that means one of their tasks is to log those issues as they happen. Every engineer takes a turn at being the magnet.