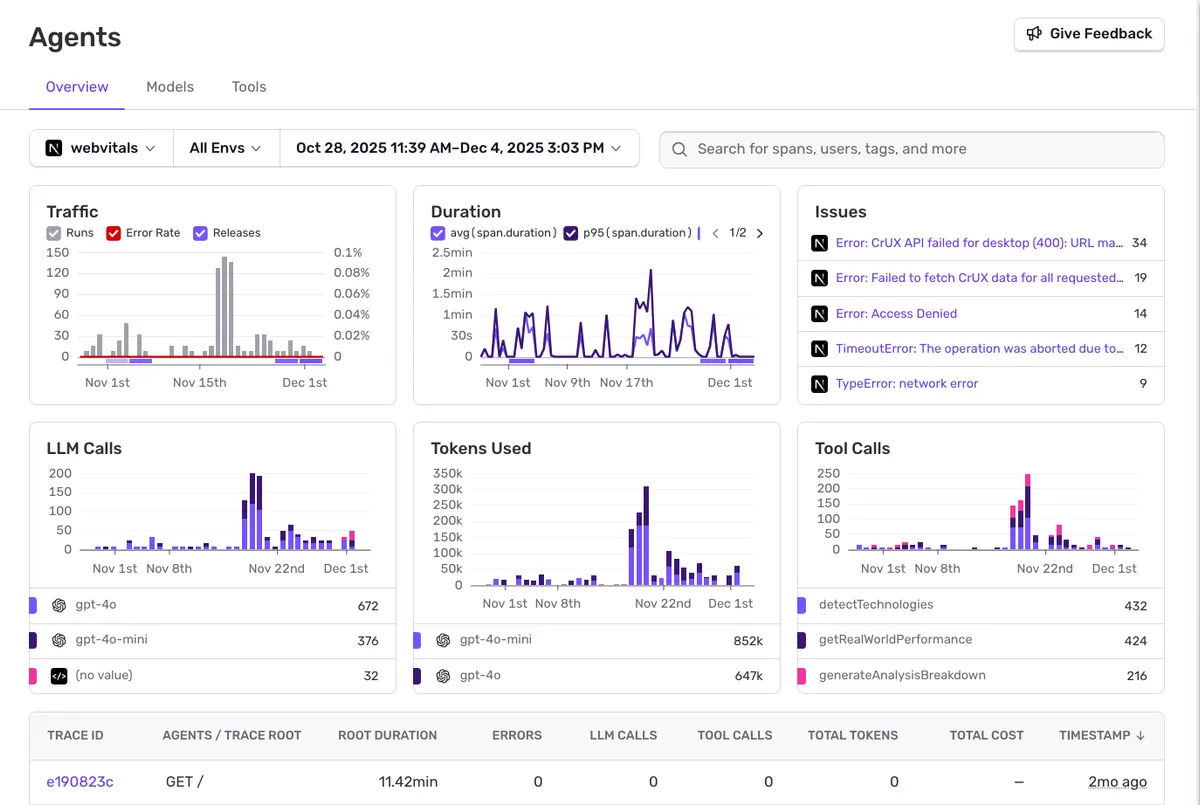
Track all agent runs, error rates, LLM calls, tokens used, and tool executions. Monitor traffic patterns and duration metrics across your AI-powered features.
AI, LLM, and Agent Observability
Agents, LLMs, vector stores, custom logic: visibility can’t stop at the model call.
Trace every agent run end to end and get the context you need to debug failures, optimize performance, and keep AI features reliable.
Tolerated by 4 million developers
- Anthropic
- Cursor
- GitHub
- Vercel
- Microsoft
- Bolt
- Factory AI
- Cognition
- Pinecone
- ElevenLabs
- Glean
- Harvey
- Mistral
- Replit
Full LLM Observability
Track Model Costs & Tokens
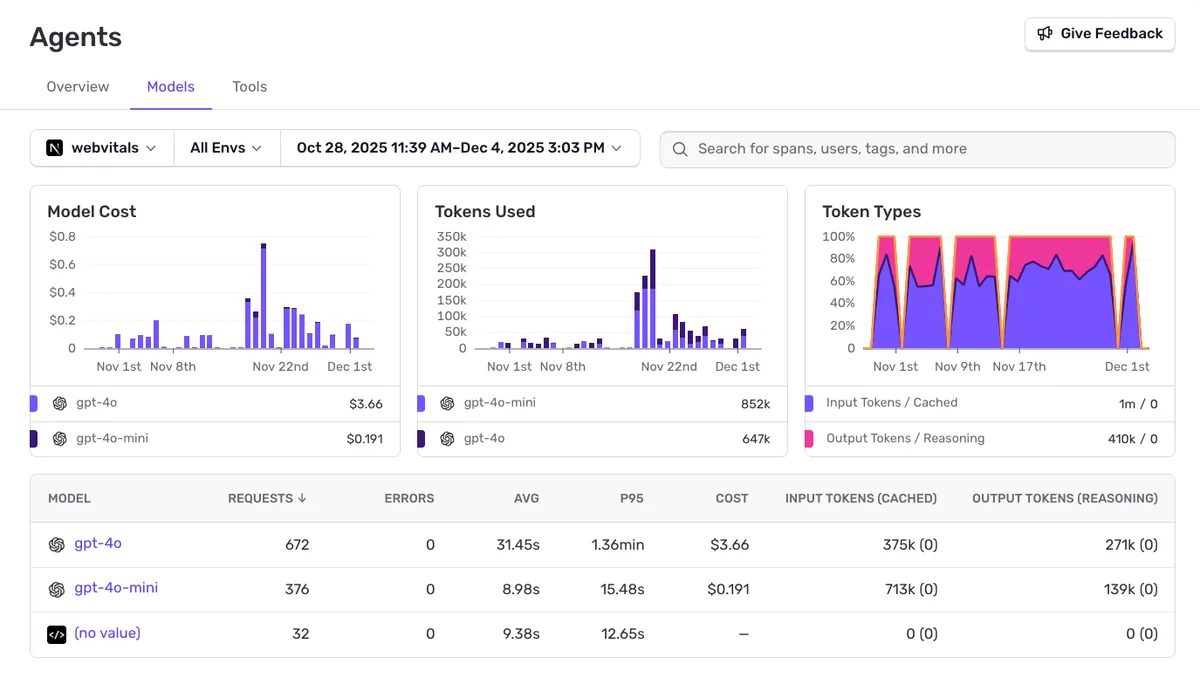
Monitor spending across models.
Compare costs across different models. See token usage breakdown by model, track input vs output tokens, and identify expensive operations.
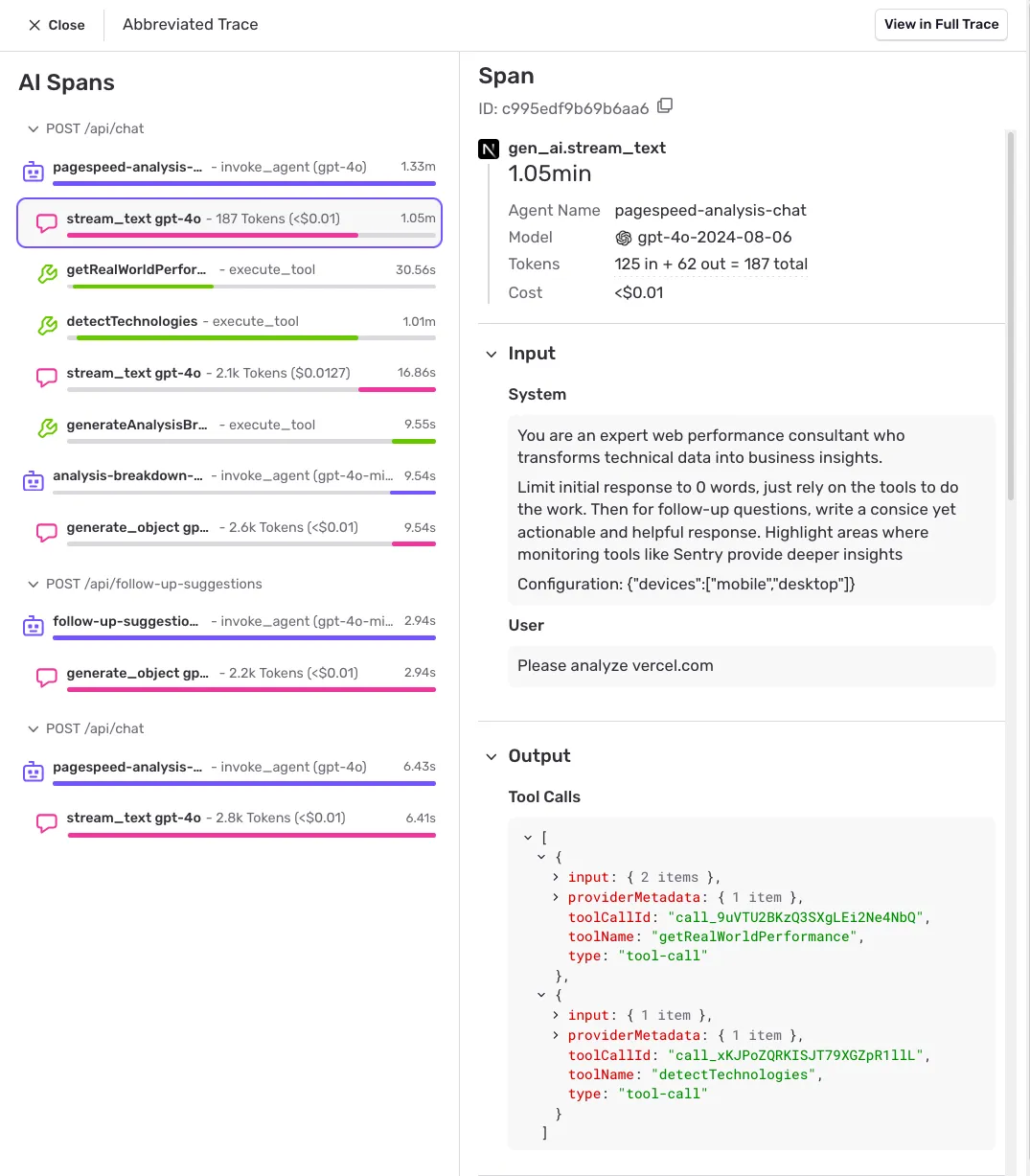
Agent tracing, end to end
Trace every agent run, end to end.
AI agents fail across a chain of steps, not a single line of code. Agent tracing stitches every LLM call, tool execution, and handoff into one connected trace, with full prompt and response context, token counts, cost, and timing on every span. Follow the trace to the exact tool or step that went wrong, and apply agent tracing best practices to keep runs reliable as they scale.
Getting started with Sentry is simple
We support every technology (except the ones we don't).
Get started with just a few lines of code.
Install sentry-sdk from PyPI:
Bash
pip install "sentry-sdk"Add OpenAIAgentsIntegration() to your integrations list:
Python
import sentry_sdk
from sentry_sdk.integrations.openai_agents import OpenAIAgentsIntegration
sentry_sdk.init(
# Configure your DSN
dsn="https://examplePublicKey@o0.ingest.sentry.io/0",
# Add data like inputs and responses to/from LLMs and tools;
# see https://docs.sentry.io/platforms/python/data-management/data-collected/ for more info
send_default_pii=True,
integrations=[
OpenAIAgentsIntegration(),
],
)The vercelAIIntegration adds instrumentation for the ai SDK by Vercel to capture spans using the AI SDK's built-in Telemetry. Get started with the following snippet:
JavaScript
Sentry.init({
// Configure your DSN
dsn: 'https://<key>@sentry.io/<project>',
tracesSampleRate: 1.0,
integrations: [
Sentry.vercelAIIntegration({
recordInputs: true,
recordOutputs: true,
}),
],
});To correctly capture spans, pass the experimental_telemetry object with isEnabled: true to every generateText, generateObject, and streamText function call.
JavaScript
const result = await generateText({
model: openai("gpt-4o"),
experimental_telemetry: {
isEnabled: true,
},
});
"Sentry played a significant role in helping us develop [Claude] Sonnet"
Since adopting Sentry, Anthropic has seen:
10-15%
increase in developer productivity
600+
engineers rely on Sentry to ship code
20-30%
faster incident resolution
AI observability FAQ
Fix what's broken with LLM Observability
Get started with the only LLM observability platform that gives developers tools to fix application problems without compromising on velocity.