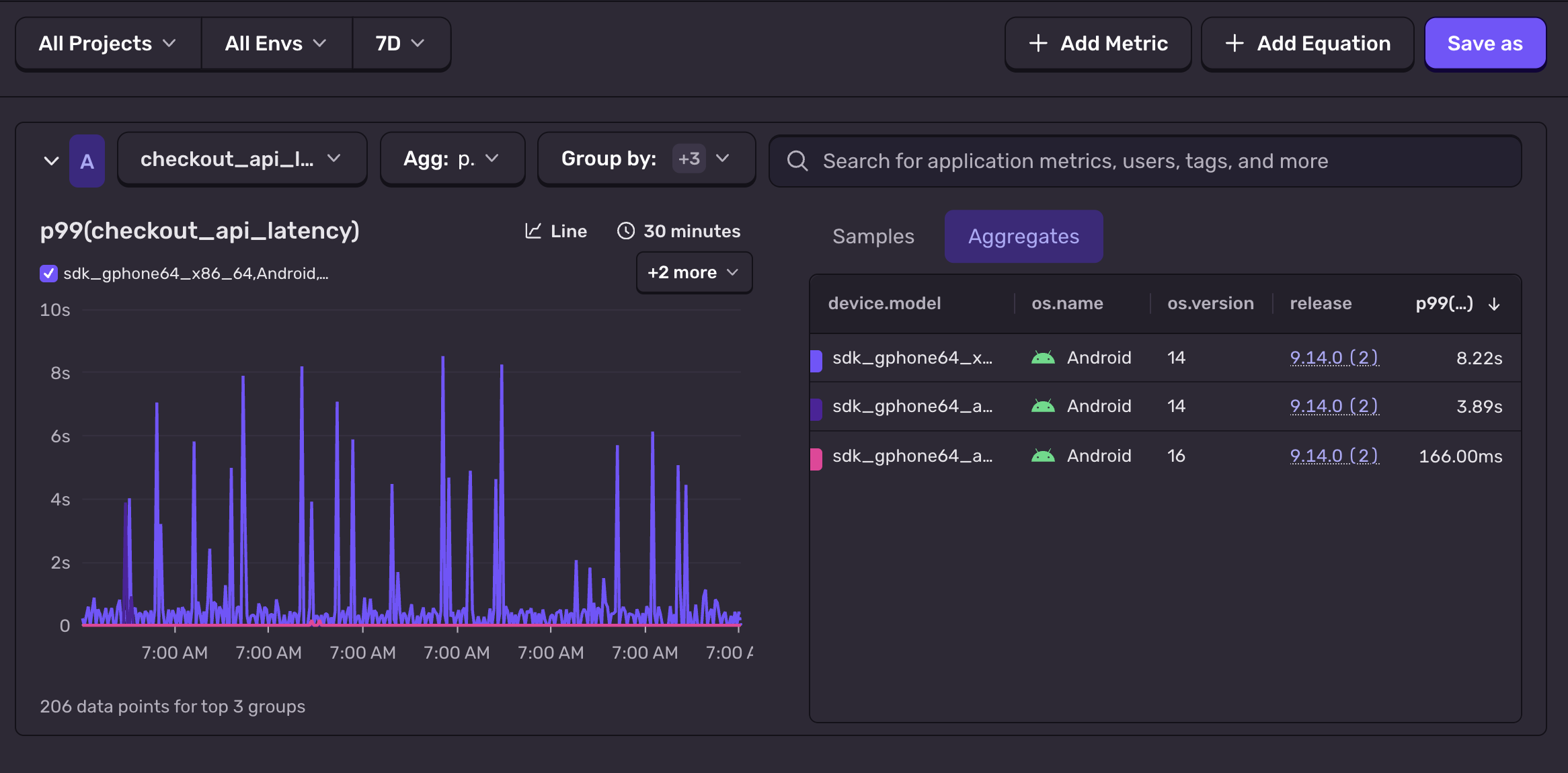
A spike isn't a number on a graph — it's a clickable path to the exact request, span, and line of code.
Drill from a p95 outlier into the slow span that produced it
Jump from a counter increment to the issue and stack trace behind it
Correlate metric movements with releases, feature flags, and deploys automatically

