
Rush is a shipment tracking and analytics platform that lets businesses build and personalize their own dashboards to manage the post-sale process with real-time data, custom product recommendations, and user feedback. Their business model focuses on low touch and user-centered design (UCD), which leaves little room for issues impacting how people experience their platform.
Rated as the top order tracking and revenue generation app on Shopify, user experience is their main business driver, so much so that Rush doesn’t have a sales organization and relies purely on the in-app experience. Most of their users come from the Shopify marketplace, which makes them quick to install and quick to uninstall, so the team focuses heavily on proactive monitoring, keeping an eye on edge cases, and sees the ability to resolve issues in production as key to the business’ continued success.
Read on to learn how Rush:
- Limits time to resolution to under 10 minutes
- Monitors release health to maintain multiple daily deployments without sacrificing quality
- Monitors and prioritizes edge cases with detailed context
- Uses Sentry for data-driven decision-making and avoids gold-plating
- Maintains an almost “bug-free” experience for their users
“As Co-founder and Product Lead, I know how important is for our business model to ensure a great customer experience. We are a data-driven solution and we operate in the big data space, where you can’t see all the issues or handle all cases or variations.”
Stanislav Stankov, Co-founder & Product Lead, Rush.
Some tools are built to scale, others just aren’t
Rush supports more than 1,500 brands – and counting – on Shopify. As the business expanded, they realized they had outgrown their existing APM tools. Some of these required an increasing amount of tinkering and support which pushed up costs, while others, put plainly, “made it a nightmare to do root cause analyses” with what they had. So they set out to find a solution that could scale alongside the team. Some vendors didn’t quite fit their business needs, with inflexible pricing structures that didn’t account for team vs business size and custom use cases.
Ultimately, Stanislav and his team knew they had to find something that would give them rich error context from the frontend to the backend, speed up the time it takes to resolve issues in production and effectively monitor and prioritize edge cases.
Currently a monolithic structure, Rush is slowly splitting up into microservices, starting at five with a goal of 20. Their solution is hosted on AWS using Kubernetes and features multiple React and Typescript frontends supported by node.js and PHP on the backend, with Aurora Postgres at the data layer.
“We needed a solution that could scale as the business grows, with actionable details, custom filters, and a user-friendly interface that gives us a holistic view of our entire environment.”
“Sentry has become part of our DNA.”
To date, brands using Rush have seen an average of 30x ROI with more than $10m in post-sales opportunities influenced through the shipping process alone. Part of that success has been the way users can customize their own order tracking pages and delivery notifications with analytics, CTAs that drive additional sales, and real-time shipment data.
Store owners are offered preloaded templates to match their brand identity, with the option to modify the app at the code level using CSS. Each template includes Sentry by default, allowing Stanislav’s team to see how a brand’s customers interact with the order tracking page, and whether any scripts are impacting performance. After that, the team monitors users’ services through their frontend projects dashboard. Since no two brands operate exactly the same, having Sentry monitor and alert the team of unexpected issues lets them maintain a high bar for UX, which in turn benefits store owners.
All of this is done during onboarding and saves a lot of time configuring, expands visibility on the frontend, with the added benefit that everyone has a basic working knowledge of Sentry.
“After we started using Sentry we got a much better understanding of the quality of the app we were building, it’s not just about monitoring and fixing issues, we have data-driven insight into how our system operates.”
Rush’s system serves roughly 2.3m calls a day and with a customer base used to an app marketplace experience where you uninstall a non-performant tool almost as quickly as you installed it, poor UX has a direct impact on the bottom line. For Stanislav and his team, the difference between a customer and ‘what could have been’ is context, so they crafted a workflow that, in most cases, means they can cap time to resolution at just 10 minutes.
They do this by integrating Sentry directly into their CI/CD pipeline to view source code context obtained from stack traces and use custom tags to configure the level of detail attached to errors depending on the log level of the application and customer tenant.
*“*Prioritizing issues is priceless for us. With that, we’re not only able to increase system resiliency and quality, but we avoid gold-plating, giving us time to work on impactful tasks.”
Over time the team has built up a ‘hit list’ of issues to keep an eye on and with custom alerts, when there’s an error, issue grouping and their consistent monitoring of edge cases helps them prioritize what to solve first based on volume or impact. Sentry’s Slack integration notifies the team on a platform purpose-built for collaboration, with the context they need to decide how to proceed.
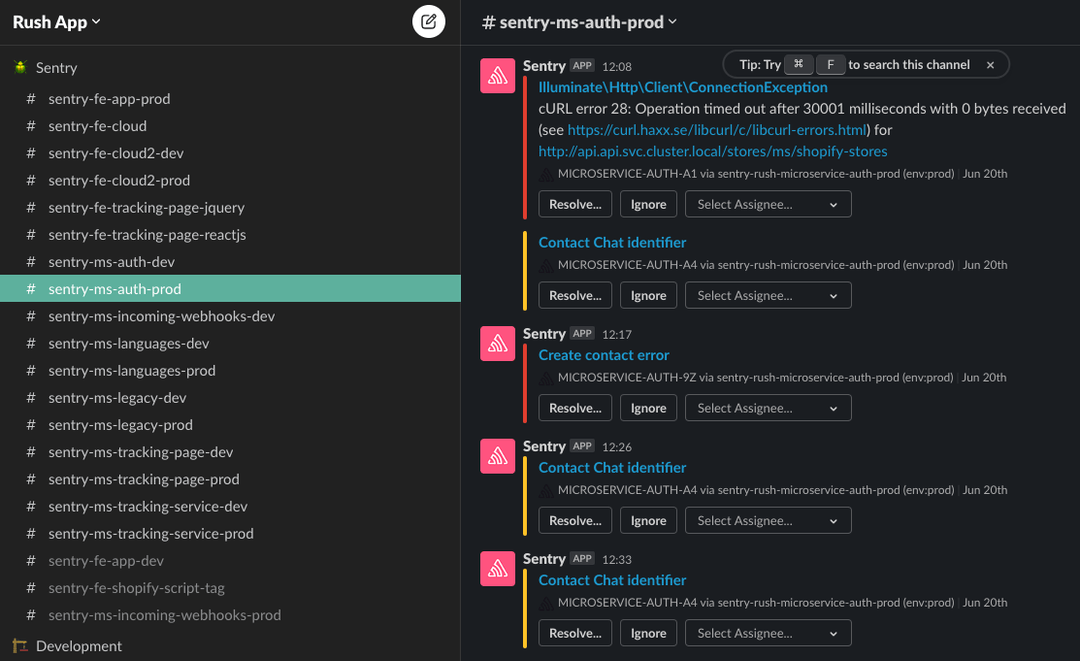
Each team member is responsible for a set of Slack channels, checking them for issues daily. When there’s an error, breadcrumbs – already enriched with additional context – helps them investigate when and where it happened.
“We prioritize having a frictionless experience rather than new features. Having unhandled issues means higher churn for us.”
Rush ships new features and updates through multiple deployments a day. Knowing that certain errors only surface at this point, they pay close attention to release health and if an alert is triggered after a deployment, their CD can automatically roll back if the error rate increases above a custom threshold, giving them time to investigate; with custom error context already attached, ready for them to tackle it in production before a user even notices.
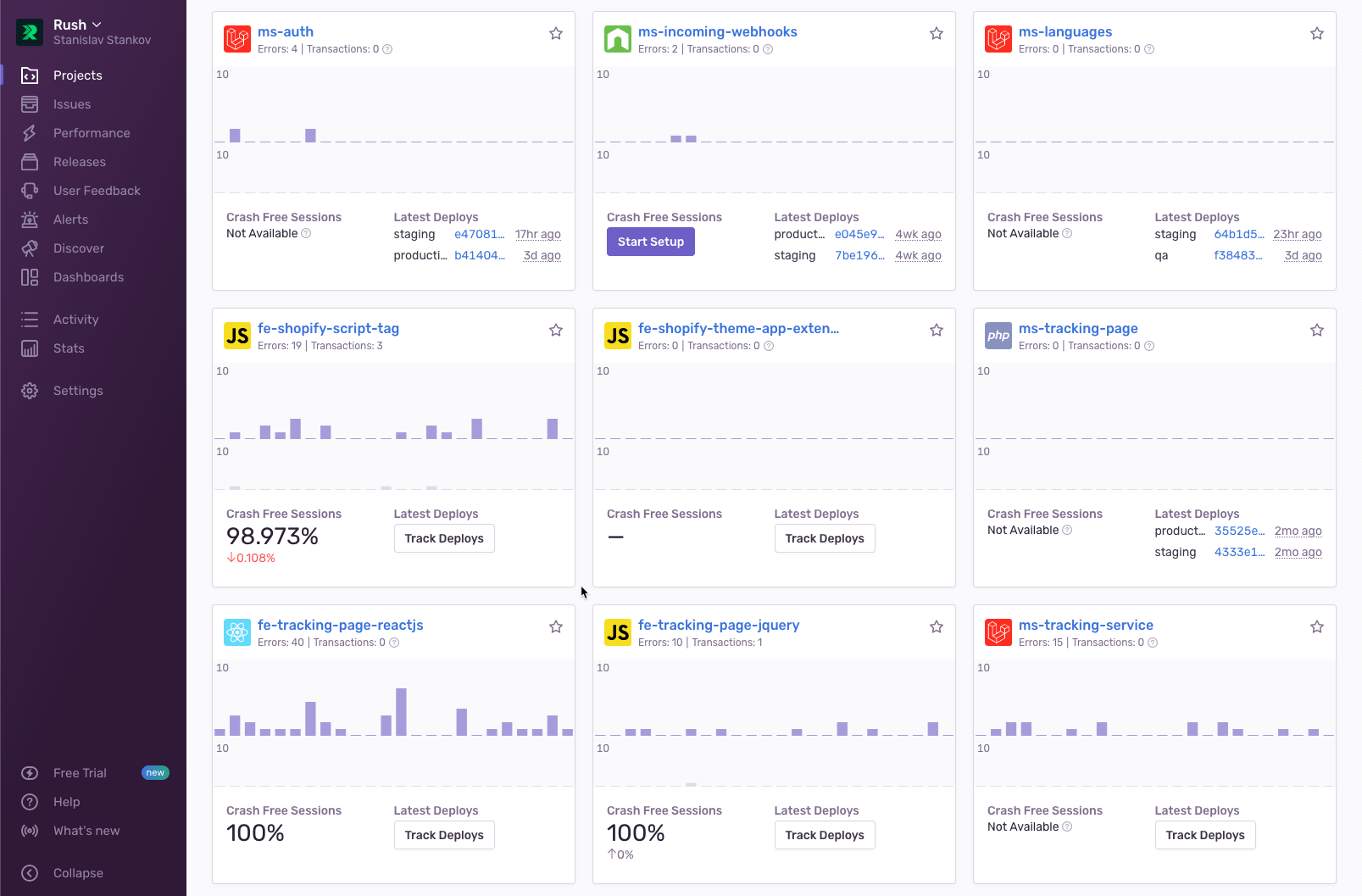
“A lot of companies use sentry for error monitoring, but we use it to determine the impact an issue has on the entire business.”
It’s not the NAT gateway
Here’s an example of how customizing Sentry to fit into how they work gave them the context to quickly understand the root cause of an issue, with most of the investigating already done for them – well, they did the tagging, fingerprinting and grouping to lay the groundwork, but you get the idea.
A recent (depending on when you’re reading this) Cloudflare outage started returning 500 errors and the team quickly identified the same pattern across multiple services having the same 500 error response. Initially they thought that their cluster’s NAT gateway was down, but Sentry pinpointed the real issue – that the request pattern and referrals introduced the error - by automatically collecting and showing them the relevant information:
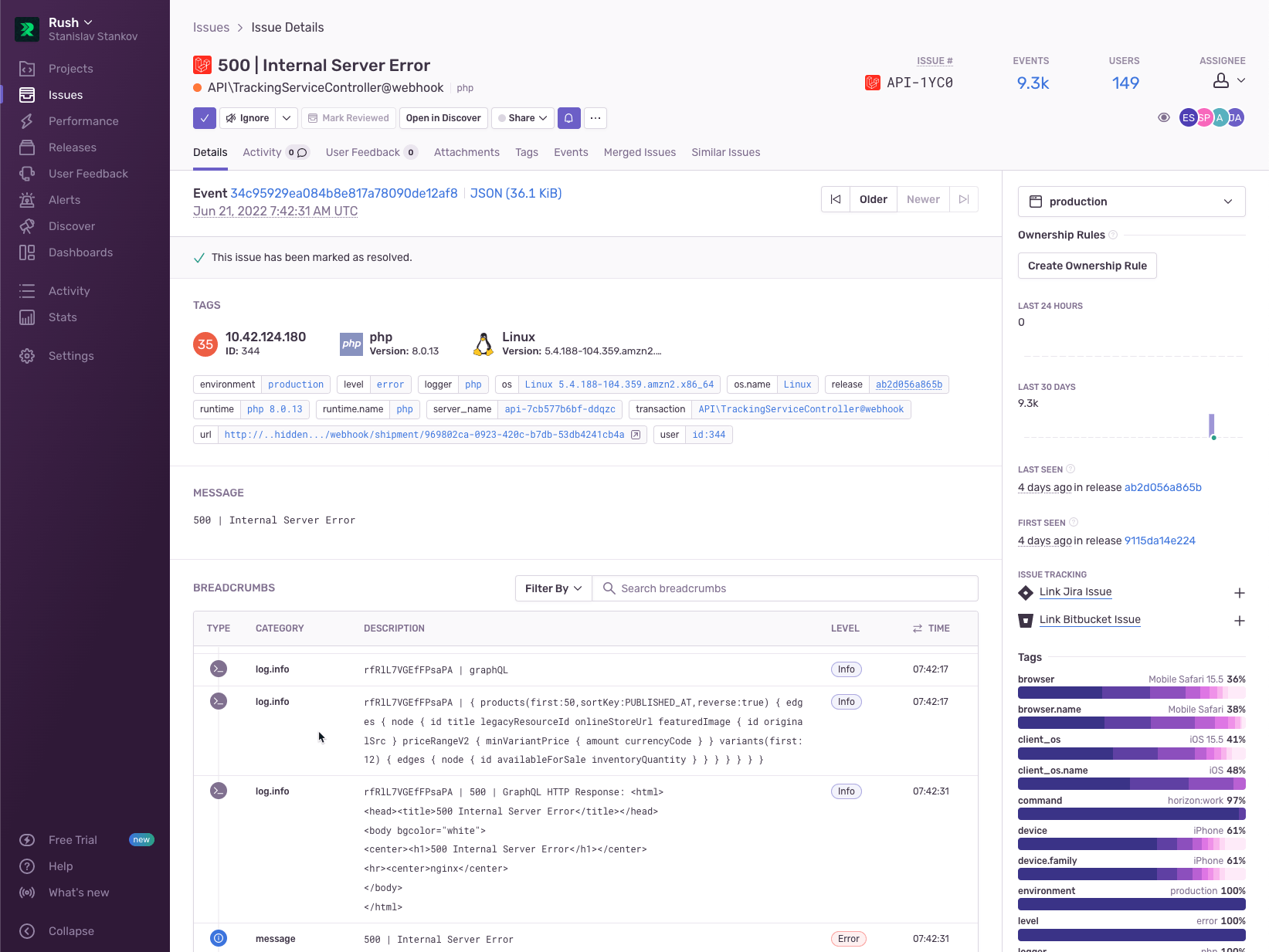
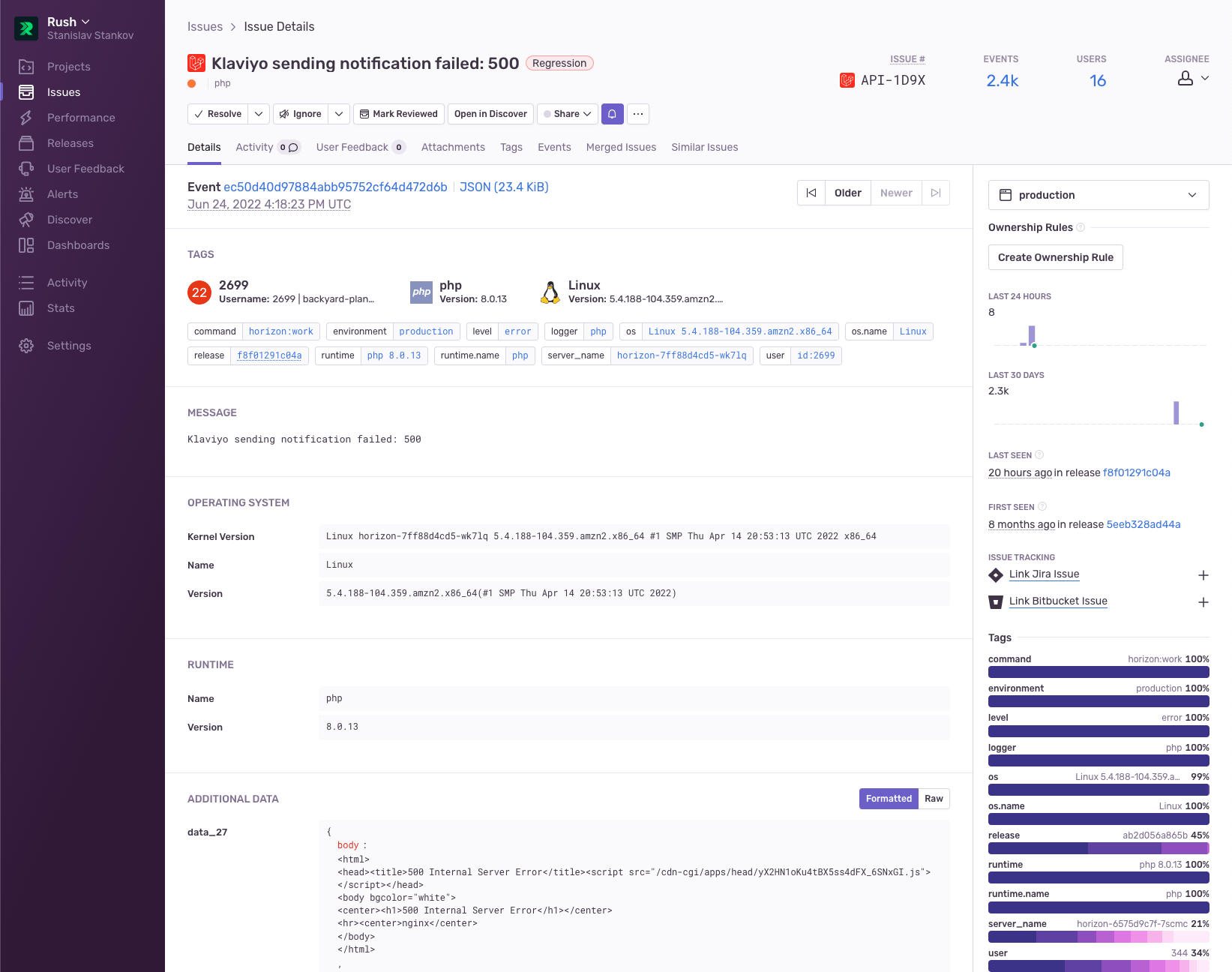
Once they understood what was happening, the team notified their customers and, after services were restored, backfilled any missing information and resent the shipping notifications.
By partnering with Sentry, Stanislav equipped his team with the tools to take ownership of what they build, save time investigating when something breaks, and get on with building awesome experiences for their rapidly growing customer base. Relying on a fit-for-purpose APM solution also means that Rush can rely on scalable tools, with the confidence knowing that whatever they build going forward, they’ll be able to monitor.
Key results:
- Limit time to resolution to under 10 minutes
- Maintain multiple daily deployments without sacrificing quality
- Rich context with the ability to monitor and prioritize edge cases on the front-and-backend
- Data-driven decision-making to prevent gold-plating
- Ability to scale as the business grows
“We’re able to resolve issues fast, less than 10 minutes in production. I don’t see us building any SaaS product without Sentry going forward.”