
Backed by sports superstars like Serena Williams and LeBron James, and named one of FastCompany’s 10 Most Innovative Companies of 2022, Tonal is a leading digital strength training solution that offers a subscription-based service with a supporting mobile app experience.
The fitness industry is no stranger to ‘smart’ equipment, and what distinguishes one product from another ultimately comes down to user experience. Product success depends heavily on stability, something Tonal is known for. Its platform is supported by engineering teams who rely on their APM solutions to help them:
- Prioritize issues with the most significant potential impact on customers
- Add context to errors and correlate them with deployments
- Reproduce and quickly resolve issues across staging and production environments
- Monitor release health to maintain a consistent production schedule
“Compared to the size of our user base and how active they are, we have relatively few users reporting bugs. We have very stable products and the goal is to keep it that way.”
Max Lapides, Sr. Manager of Mobile Software Engineering, Tonal
Tonal’s hardware is supported by a native Android application, integrated using a custom distribution system, and complemented by a mobile app for Android and iOS, built in Flutter. Developers working in Go, Dart, C/C++, Kotlin, and Swift build and deploy features on a strict schedule, with a clear focus on feature parity across platforms.
The mobile app initially just supported progress tracking but has grown into a fully integrated lifestyle offering with a proprietary Strength Score, thousands of guided workouts, planning tools, articles, perks, and product news.
Platform stability above all
Ranked as one of New York Magazine’s best smart home training solutions 2022 and Men’s Health’s best connected cable machine 2022, Tonal literally sets the bar for smart home trainers. In maintaining that standard, developers have a slightly different approach to most when making sure their product ‘does what it says on the box’… instead of reducing issues, they work towards avoiding them altogether.
“We don’t have the mindset of reducing errors and crashes, we don’t have those, they’re the exception, not the rule.”
Wait, no errors or crashes at all? Technically no, but in reality, all the heavy lifting happens behind the scenes. To maintain application stability, developers on the mobile team need the tools to enrich errors with detailed context, quickly follow a timeline of actions leading up to an issue, and tie errors to releases.
Implementing a workflow for a bug-free user experience
Okay, so it’s not necessarily that there aren’t any errors, but rather, preventing the ones you do have from ultimately impacting customers. An important part of that is monitoring and integrating automated error reporting into the team’s development workflow. Most users probably don’t know what that means or even care; but when they’re asked what they think of Tonal, one of the first things they often comment on is the fact that it works and doesn’t give them any trouble.
To speed up reproducing and resolving issues across production and staging environments, developers tag errors with additional context like the version of Flutter the release was built with, version name, build number, device operating system, device type, and more.
“What often happens with production errors is that the same issue generates multiple related errors. With this level of context, we can get straight to the root cause and fix it.”
Using Debug Symbols to symbolicate their obfuscated logs – including those of 3rd party frameworks – gives them additional context from stack traces. For example, this stack trace is redacted and for all intents and purposes, useless for debugging:
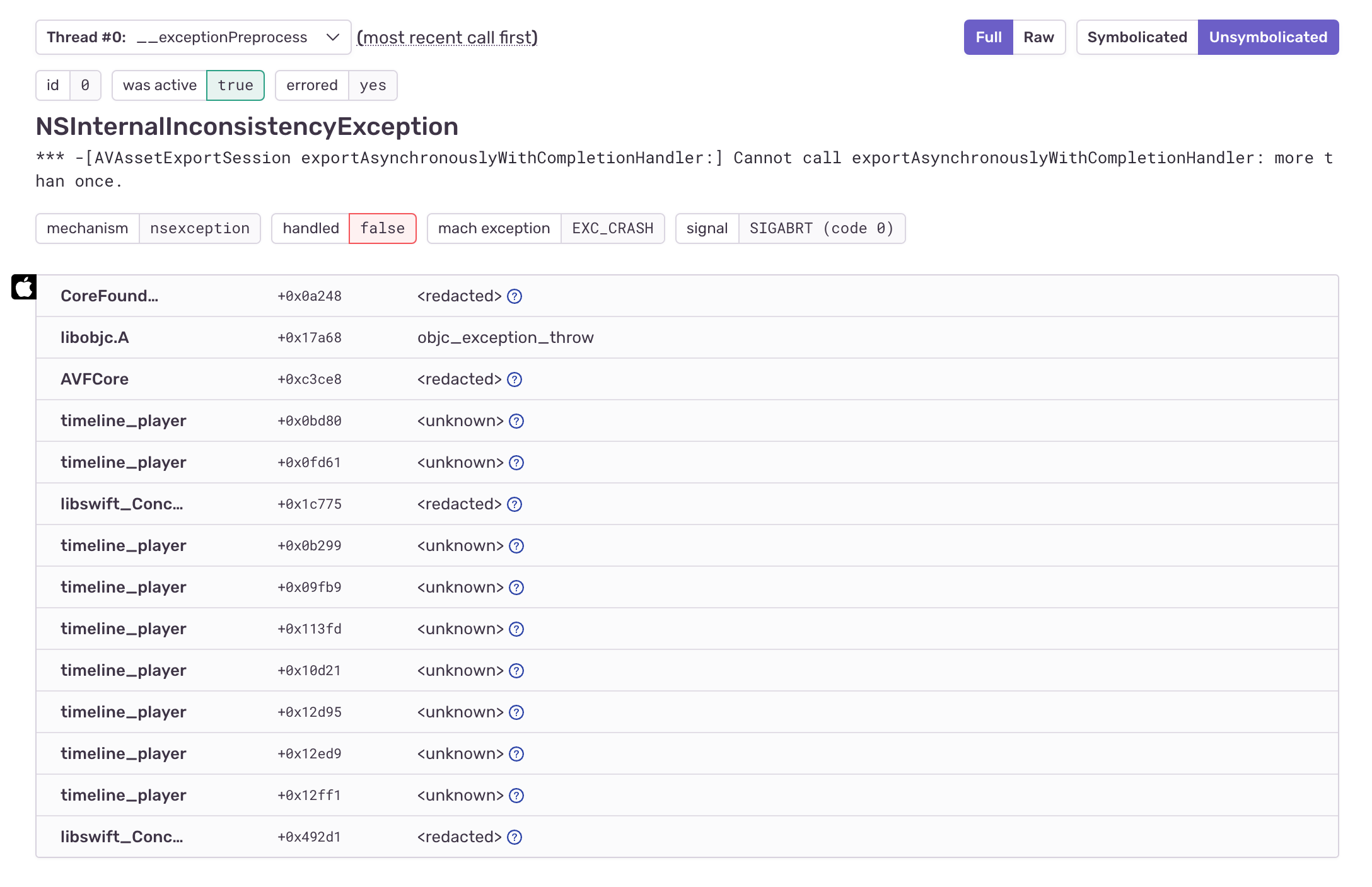
But once they’ve uploaded their debug symbols to Sentry, they end up with a symbolicated stack trace:
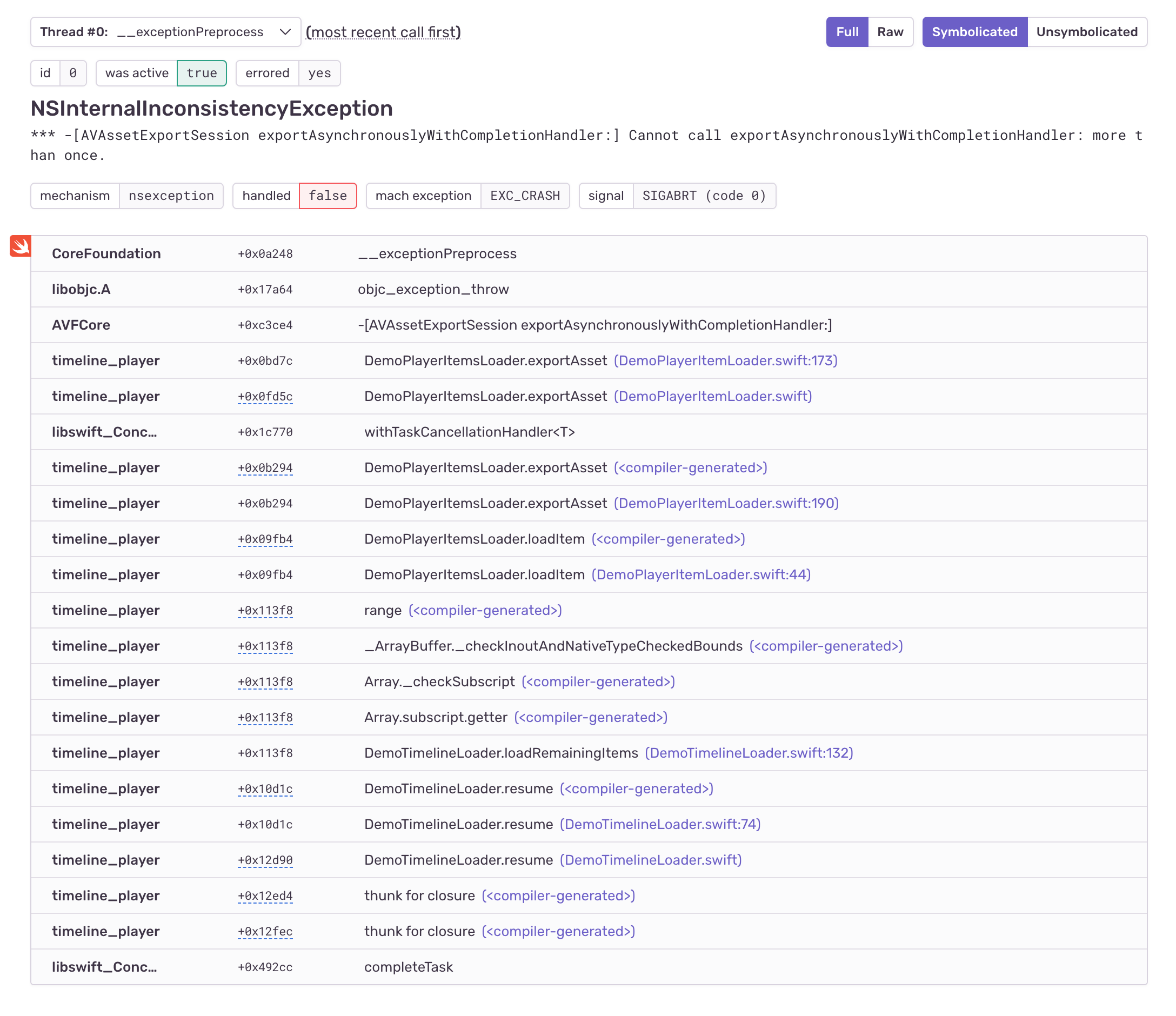
“Without Sentry, we would need to collect these debug symbol files – which Sentry collects automatically from App Store Connect and from uploads from our CI system – and then manually use them to convert the obfuscated data to something human-readable.”
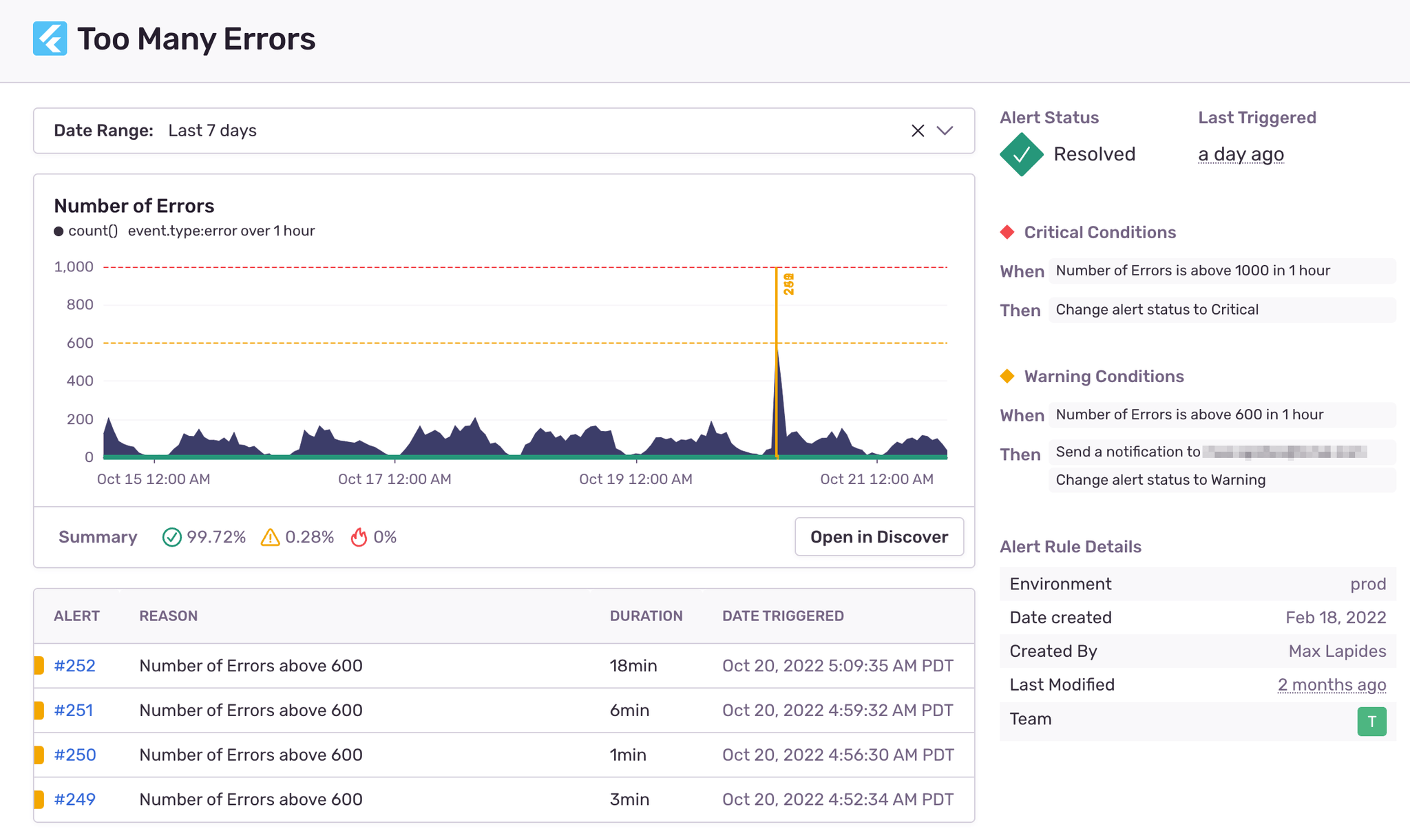
Custom alerts let Max’s team stay on top of the volume and frequency of new errors and issues over time, highlighting those with the highest impact, and helping them allocate engineering time more strategically:
Sentry’s Slack integration notifies the relevant developers of new errors once an issue is assigned. Having also configured breadcrumbs, developers investigating the issue not only see a timeline of a user’s actions that led to an error, but all the context needed to reproduce and resolve it:
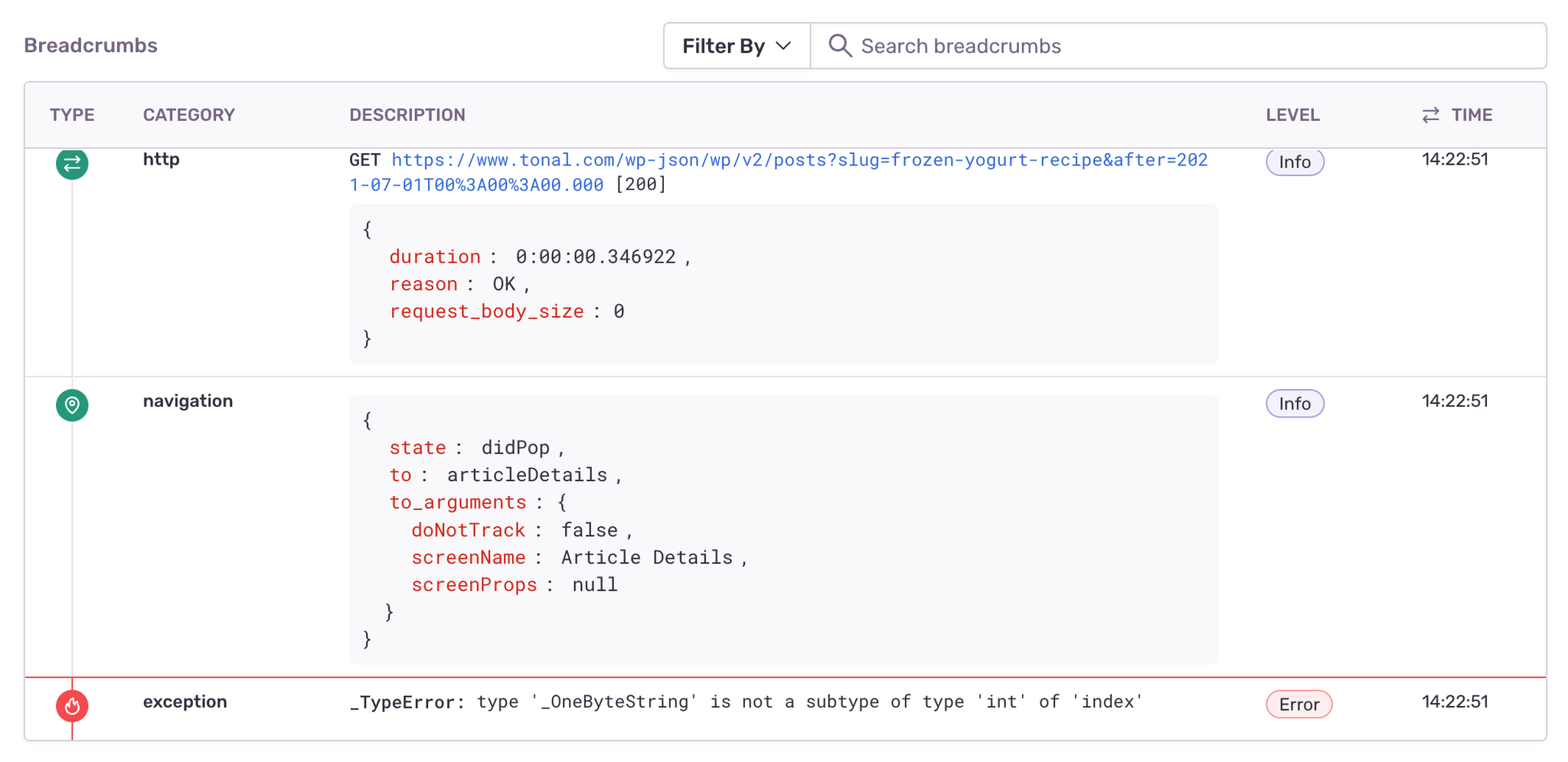
“At a certain point, I realized that these user events that we’re already tracking for analytics purposes also represent a stream of the user’s actions in the app that’s useful for debugging. So, we are now also sending these user events to Sentry as error breadcrumbs that let us see exactly what a user did before an issue occurred without leaving Sentry.”
For example, a quality assurance engineer looking at edge cases during new feature testing might pick up on a UI issue. Sentry shows them real-time data on the issue like the HTTP requests a user made leading up to it, and any navigation they did, with detailed context including the team responsible, Flutter version, and build number, making it easier to file an actionable bug report that’ll include enough detail on how to reproduce and ultimately resolve the issue:
Finally, and something Max finds valuable to keep overheads down, is how his team uses inbound filters to prevent older builds of the app from affecting their quota. Sentry’s filters and quota management tools let teams exercise fine-grained control over which events and attachments count, disregarding duplicates or those that might have already been fixed.
Release health as a buffer between QA and deployment
Max’s team follows a strict two-week sprint and deployment cadence that’s been in place since 2019 and hasn’t once deviated. This level of consistency and predictability with releases translates well to Tonal’s overall model of stability and consistently performant user experience. The thing about mobile, however, is that there’s no such thing as fixing code on-the-fly once it’s been deployed.
We need to rebuild the app for both Android and iOS platforms, submit it for review, which usually takes 24-48 hours, then we can release it to both Google Play and the App Store, and then we have to wait for users’ devices to automatically update, which can take up to another 3 days for critical adoption.
That’s why Tonal holds their builds in QA and monitors them on the releases dashboard for about a week before deployment. Releases are standardized, with individual build numbers, and once they’ve passed QA the team declares the latest build number the “gold master,” ready to ship to production.
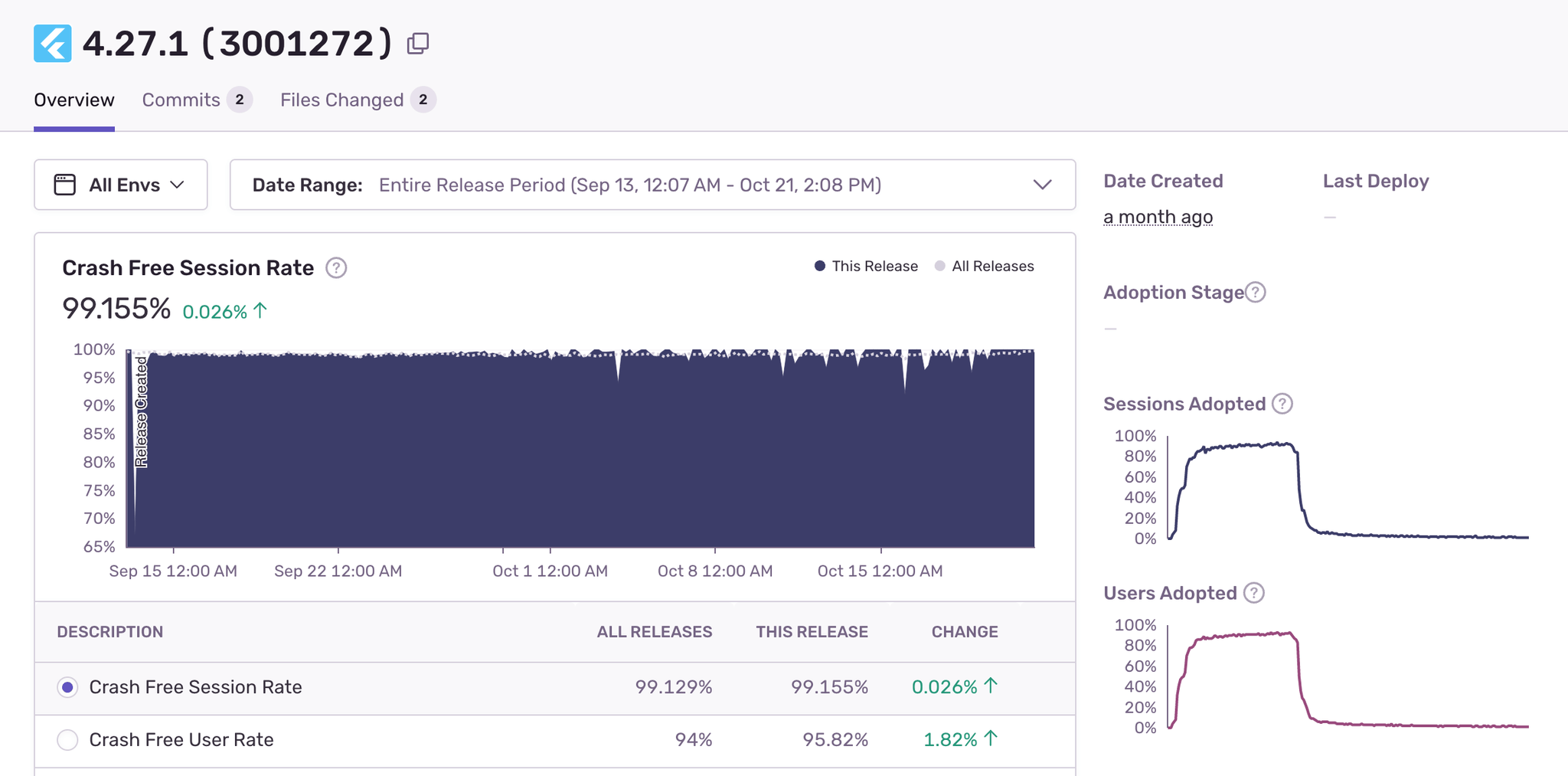
“When a critical issue is identified with Sentry we’re generally able to fix it within 48 hours. The goal is that these issues never hit production.”
With a focus on platform stability, resilience, and user experience, Max’s team combines their development experience with custom Sentry solutions, giving them the ability to:
- Proactively monitor for errors, with detailed context baked in
- Prioritize those with a direct impact on platform stability and UX
- Maintain a strict release schedule without sacrificing quality
- Analyze in-app user behavior to speed up time to resolution and,
- Maintain their competitive edge in a crowded market
“Sentry helps us maintain platform stability and prevents us from shipping something that has a direct effect on our users. A good day for us is when we don’t have crashes… which is every day.”