
Headquartered in San Francisco, Forethought is a leading AI company providing customer service solutions that transform the customer experience. As a high-growth startup with 2x growth in their engineering team, leadership faced growing complexity, a backlog of issues and challenges measuring the impact and health of their services.
“As our team of engineers grew from 6 to 40 we had to split up and while that made sense from a product management and tracking perspective, we didn’t anticipate how difficult it would be to determine ownership of issues that were happening in production, and the knock-on effects.”
Jad Chamoun, Engineering Manager, Forethought
Growing pains
Forethought’s engineering team processes 52 million requests per day and maintains common services between other internal teams, infrastructure, data, and tools. But as the team grew from 6 engineers to 40 – with the goal of doubling that number by 2023 – they quickly realized the processes that used to work weren’t going to cut it anymore.
As they added more engineers, the original team split into five, adding complexity and confusion to sprint planning. This made it hard to determine ownership of issues and contributed to a growing backlog of JIRA tickets.
In the midst of this it became increasingly difficult to measure the impact and health of their respective services, figuring out which team was responsible for what, and making decisions on when to roll back certain releases.
“Our Jira backlog became increasingly noisy, especially as we added multiple projects, which impacted our ability to monitor release health.”
Increasing developer autonomy to decrease ‘noise’
Forethought hosts its solution on AWS, using Kubernetes along with Spinnaker and Flux for orchestration and continuous delivery. The product features a React/Redux frontend in Typescript supported by a Python backend leveraging the FastAPI framework and Pydantic for data validation. At the data layer they use MongoDB, and Redis and ElasticSearch for optimized read and search queries.
When searching for a solution, engineering manager Jad Chamoun knew they needed a tool that supported their tech stack and could help:
- Define ownership to increase developer autonomy and reduce noise
- Prioritize issues
- Track team performance
- Monitor releases and,
- Resolve issues faster
Defining ownership for faster resolution
Since they were already getting value from Sentry’s out-of-the-box Python integrations, Forethought doubled-down on Sentry and took full advantage of performance monitoring, API integration and discover.
Having identified ownership as a hurdle for continued growth and success, Jad’s team integrated their GitHub CODEOWNERS file with Sentry. This allowed them to divide up and assign responsibility to specific teams, giving them greater autonomy and speeding up resolution; now errors are filtered by team, automatically triaged and then assigned, instead of everyone getting all the errors all at once. It also added an additional layer of granularity to distributed tracing, helping them break up projects into more than just front-and backend issues.
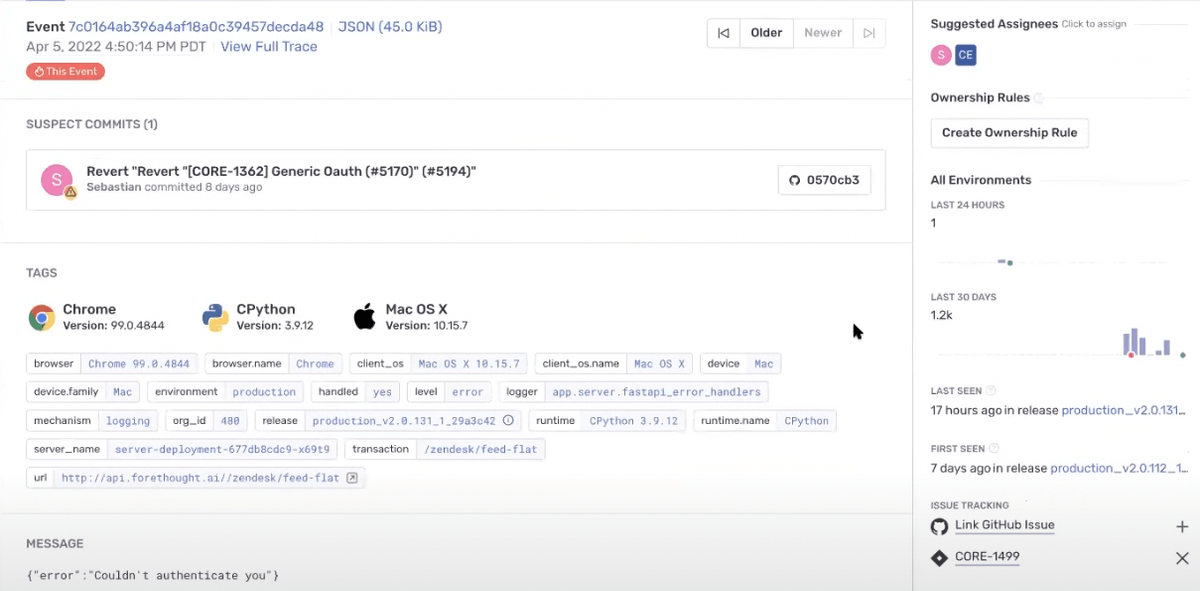
Using Code Owners to Define Issue Ownership
“Code owners has become a single source of truth for us, there’s no more ‘no, it’s someone else’s job’.”
Inbox Zero
When it came to working through their backlog of JIRA tickets, and staying on top of them, Forethought implemented quarterly bug-bashes… think of them as a zero-inbox for errors where everyone tackles everything and wipes the slate clean. But what about the time in between bug-bashes? Unresolved issues would still pile up so Jad started running weekly audits using Sentry Alerts. Adding this additional layer gives the team insight into the volume of errors over time, highlighting those with the highest impact, helping them allocate engineering time more strategically.
*“*I had to be able to balance my engineers’ time between fixing bugs and building new features, for that to happen we needed a solution that helped us stay on top of our backlog.”
The core engineering team runs deployments an average of 2.5 times a day, so the ability to manage releases and see a timeline of the actions that led up to an error is invaluable. Adding further value, Jad can see who was working on a specific piece of code at the time the error occurred, investigate how it happened and with code owners automatically assign it to the right team.
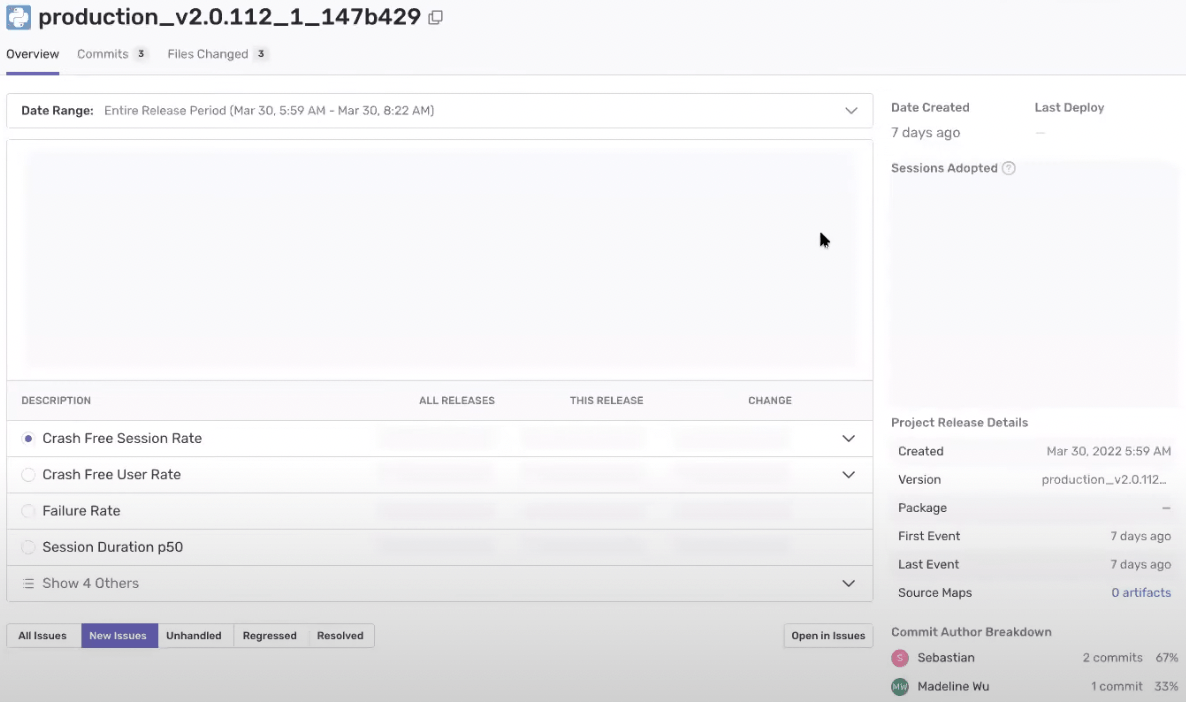
“We release up to 2.5 times a day and in order to keep that pace, we need really good release health and heuristics.”
By attributing distinct identifications to organizations within their ecosystem, Forethought can see which customers are impacted by a particular error, how many times a failure on an API call happened and any fluctuations in transaction volumes. They’ve enriched this process by setting up alerts to fire when a failure rate hits a custom threshold, then quickly identify where the issue came from and how to replicate it. Once a threshold has been hit, a new issue is opened and routed through code owners to the core services team.
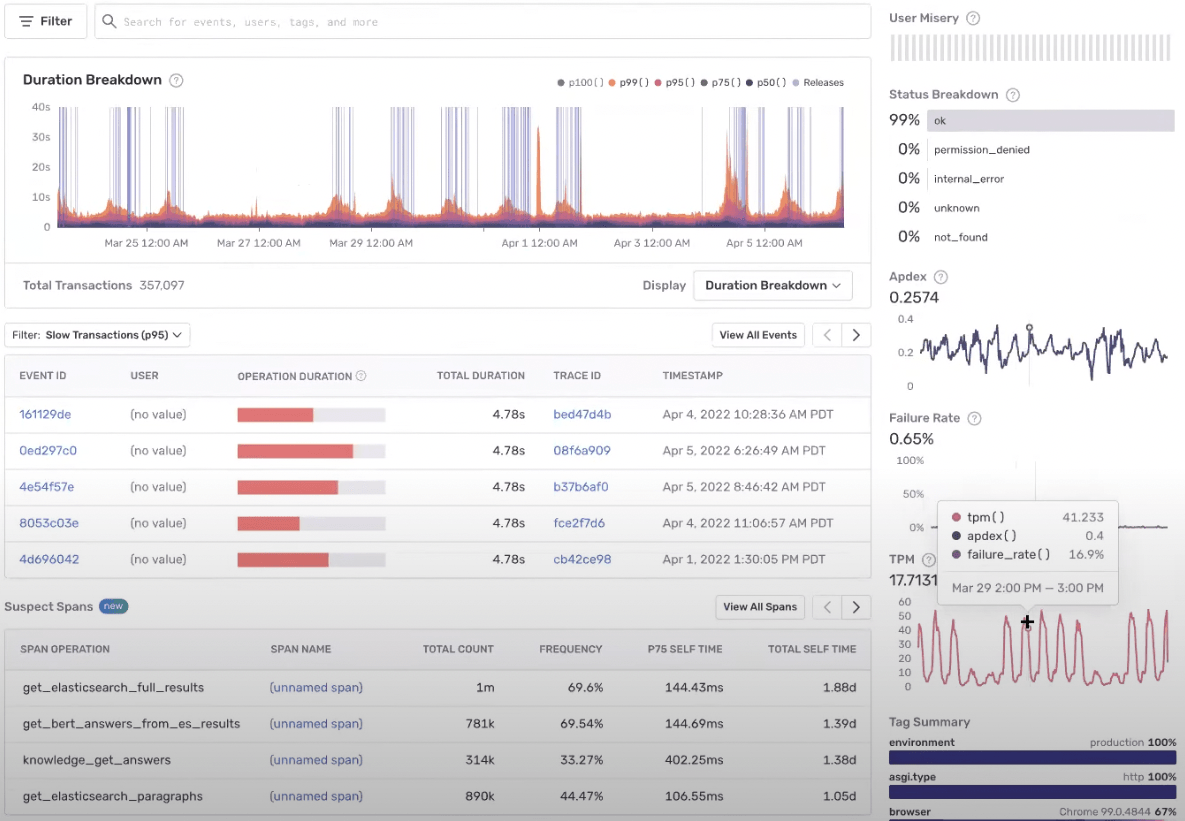
Leveraging Alert Thresholds
At this point, Sentry’s Slack integration comes in handy, as an error notification is sent directly to the channel of the responsible team – instead of everyone getting all the alerts in a single channel, trying to figure out who’s going to tackle it – where members can communicate within the channel and resolve it fast.
Jad’s team also leverages the Sentry API to investigate issues with custom-built connectors for internal tools, like Zendesk. This lets them to deep link into specific issues, reducing the amount of ad-hoc questions they get from outside teams, helping them resolve and debunk issues themselves. Using Sentry tags and identifiers, the team creates a tag for each job ID so when there’s an error they know exactly where to look.
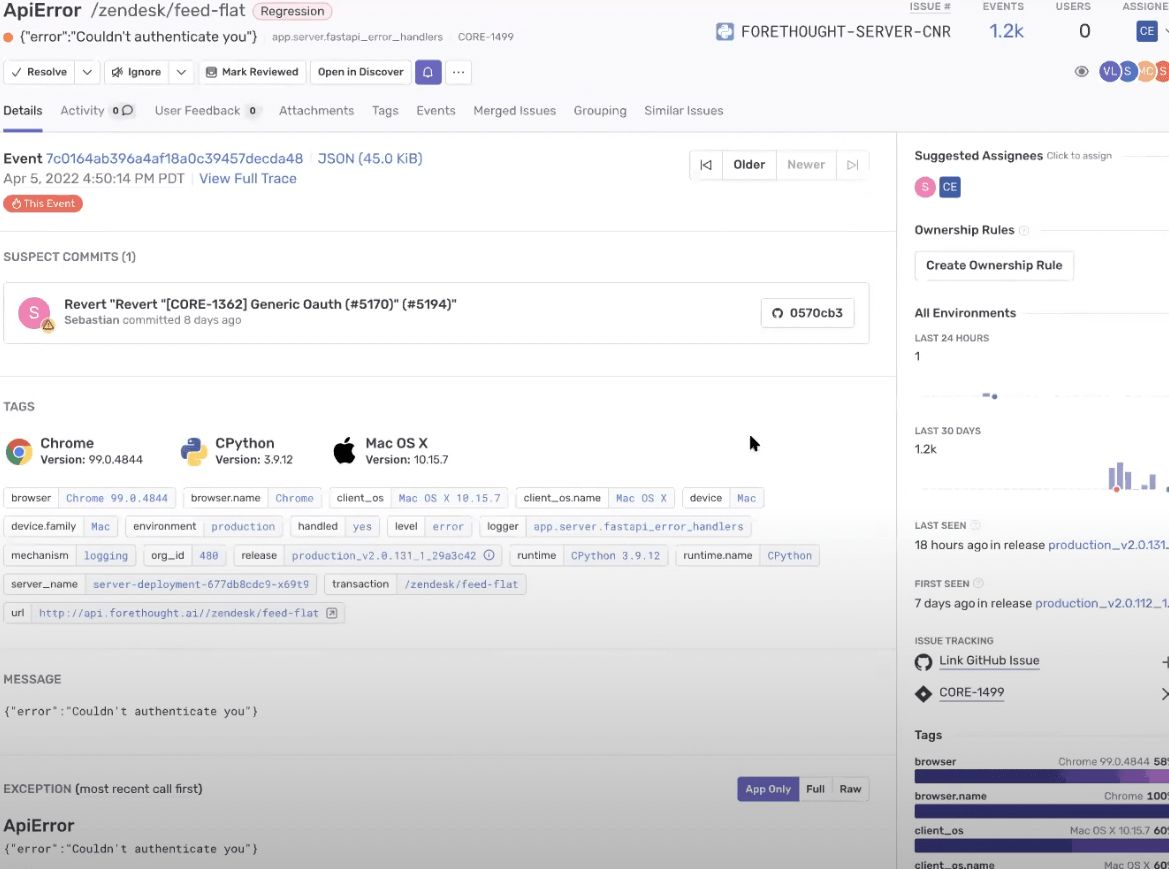
Leveraging Sentry’s API to Enrich Internal Tools
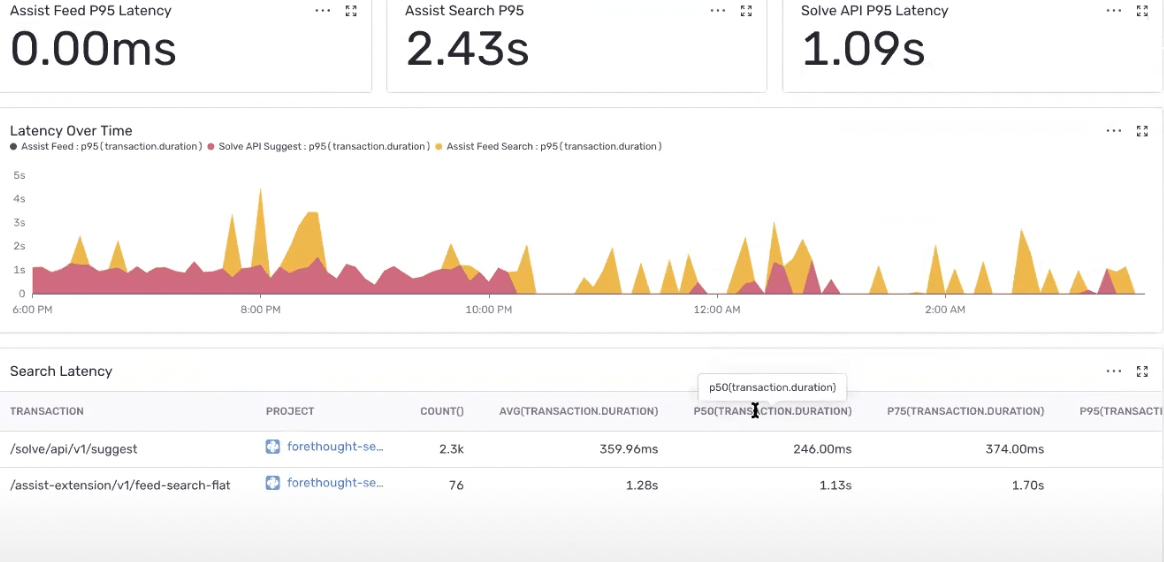
“Performance lets us keep an eye on slow requests and we’ve cut search latency by between 20-30%.”
Custom dashboards for detailed insights
For high-level, real-time insights into their environment, Jad’s team uses Dashboards to keep an eye on the highest-priority issues as they’re happening and the number of total issues happening at any given moment. They’re able to narrow these down to only core engineering’s list of issues and with the JIRA integration, see whether a ticket has already been opened or, if not, take action immediately or add it to a sprint.
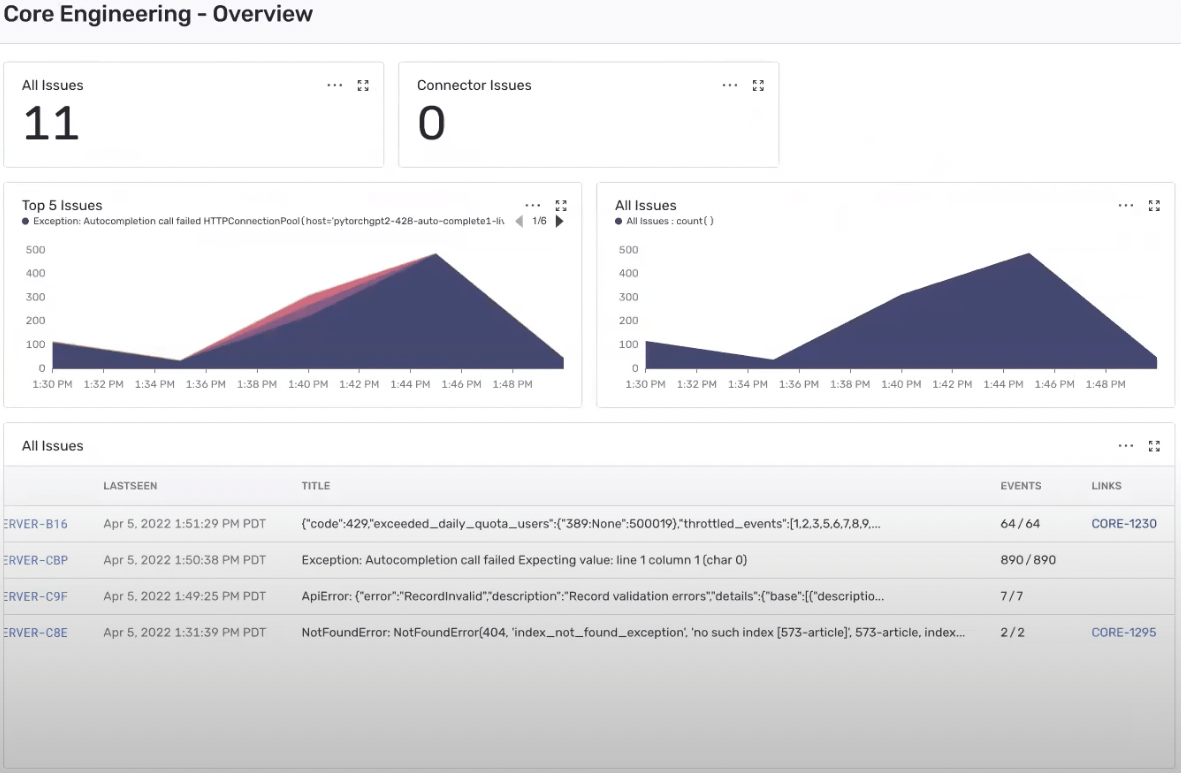
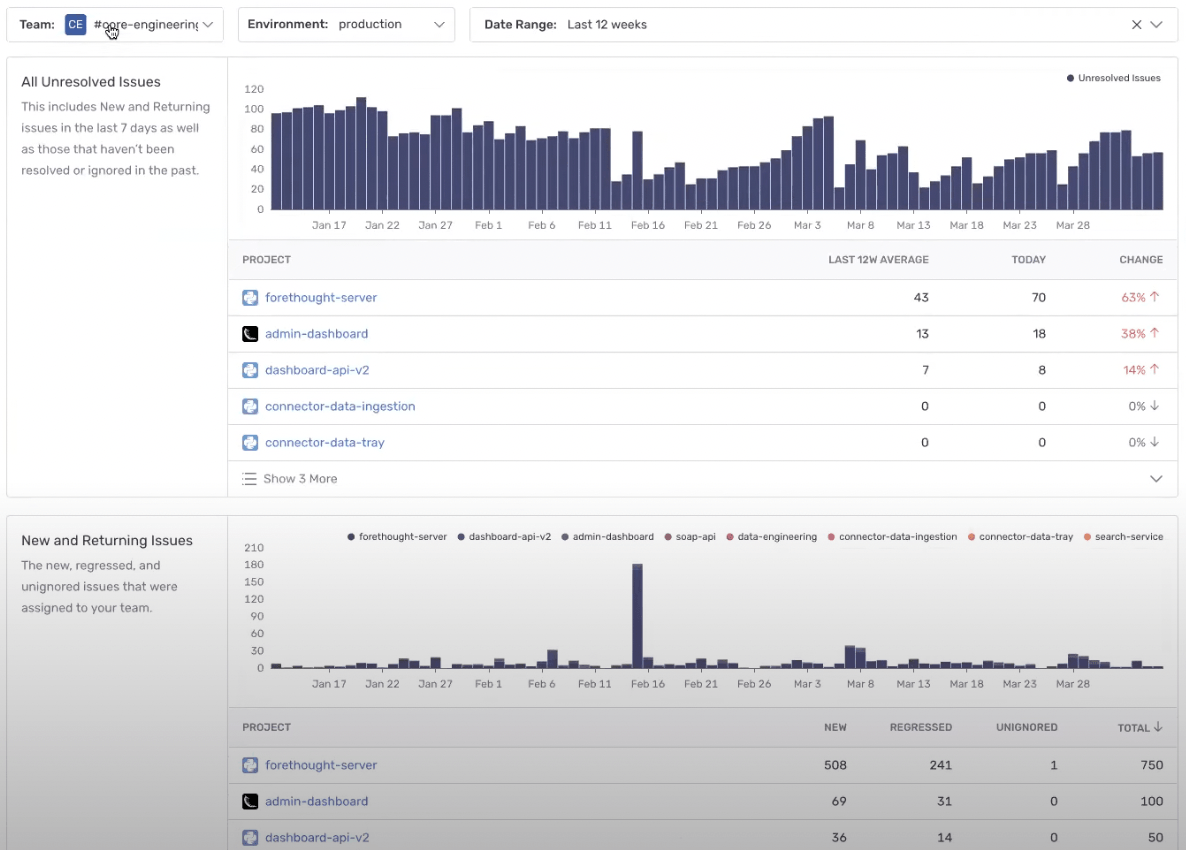
The core engineering team also uses a dashboard for statistics on issues, filtered by team, over time. With this they’re able to see historic data on unresolved issues and whether they’re improving or recurring. The most important metrics Jad keeps an eye on here is how many new errors they’re introducing and the number of regressions they’re getting in production, which helps them decide when and where to double down on code.
“We’re a high-velocity team, we move fast, but we shouldn’t compromise quality.”
Time to resolution is another key metric for the team. Before code owners, with their backlog of issues, time to resolution suffered. Now that they can filter which team owns which particular error, combined with Sentry audits, time to resolution has decreased from months to just days and in some cases hours.

Team planning and development
Finally, Stats give Jad the tools to better define internal OKRs or service-level objectives within his team. Keeping an eye on time to resolution, new issues or even latency for internal teams, he’s been able to add those metrics into deliverables which has improved how teams are being managed. These dashboards are used to report to upper management and measure how they’re progressing towards goals with regards to the quality of their work.
With Sentry, Forethought has cut through the noise, given developers more autonomy, improved the health of their teams from a management perspective and equipped them with the tools to succeed at scale.
Key Results:
- Scalability and improved ownership of issues across teams
- Reduced time to resolution by up to 94%
- Confidence in release health while deploying on average 2.5 times a day
- Improved search latency by 20-30%
- Internal apps integrate with Sentry API for easy investigation
- More strategic about team growth and management
Forethought has a host of open positions, and Jad is on the lookout for backend, DevOps and Data engineers. Check them out if you’re looking to join an awesome team.