
Gorgias is a multi-channel eCommerce helpdesk service for small to medium businesses. As a rapid-growth startup with 30+ eCommerce integrations supporting 9,300+ brands, including Marine Layer, Nomad and Try the World; understanding and resolving issues in production are essential to maintain a platform that helped their customers generate more than $1.1 billion in revenue in 2021.
“When we release a new feature or project we monitor Sentry very closely to see if there are new errors and resolve them very quickly - in a matter of hours I’d say.”
Alex Plugaru. CTO, Gorgias
Tackling issues in production
Gorgias runs a large, distributed system hosted on GCP using the Google Kubernetes Engine and features a Typescript frontend supported by Typescript & Python on the backend. They also support different connected apps and 3rd party integrations, so monitoring and resolving issues in production directly affects users, and deploying new releases to this complex ecosystem introduces unpredictable variables.
With 60 engineers and counting, teams expect their tools to scale as they grow without introducing additional complexity. For them, error reporting in itself isn’t enough. They need detailed visibility and context into errors, with the ability to run tracebacks and group issues for fast investigations. JavaScript, in particular, can be challenging to get a good trace record so a solution that supports that, with Linear integration, is essential.
“We have a lot of integrations with 3rd parties and sometimes those systems don’t behave as expected.”
Less time investigating = more time building
When Gorgias was founded back in 2015 Sentry was one of the first tools they added. That said, Alex and his team regularly review the market for best-in-class solutions and in his own words, “every time Sentry comes out on top.” Detailed SDK documentation, easy integration with their code base, paired with rich context into errors and the ability to monitor releases mean developers spend less time investigating and more time focused on their users.
“Sentry is different from other solutions out there. It really does the best job at issue grouping and tracing for languages that are notoriously difficult to track.”
The inherent complexity of their environment means Alex’s team needs the ability to assign ownership of issues across multiple platforms to the relevant people, and triage fast with detailed visibility into when and where an error occurred.
Gorgias was part of the original beta-testing group for Codeowners and continue to get value from it by clearly defining responsibilities, with the additional benefit of improving overall developer autonomy. For more context into issues, they use customs tags to enrich errors and integrated their source maps with Sentry to get additional source code context from stack traces.
Once an alert is triggered, Sentry’s Slack integration notifies only the relevant people, who work their way back from the point that an issue occurred using Breadcrumbs, reproducing and resolving it before it impacts their users.
Shipping new software with 99% uptime
Gorgias ships product updates and new features through an average of 10 deployments a day. Managing releases with a keen focus on edge cases helps the team maintain the speed at which they’re able to respond to issues in production and the quality of the software they ship.
They recently released a new voice integration built on top of Twilio, giving shoppers the option to call a brand’s customer service while allowing their agents to work from a single platform. Sentry was “instrumental” in making sure the deployment went smoothly and that the team had real-time visibility from the front-to-the-backend. Combining continuous deployment systems like ArgoCD with Sentry and canary deployments, Alex’s team ensures that deployments don’t affect the bulk of their customers.
If an alert is triggered after a deployment, the CD automatically rolls back if the error rate increases above a custom threshold, giving them time to investigate the timeline of actions that led up to it and who was working on that piece of code. Finally, monitoring the stability and adoption of each release and comparing past releases has streamlined future planning cycles.
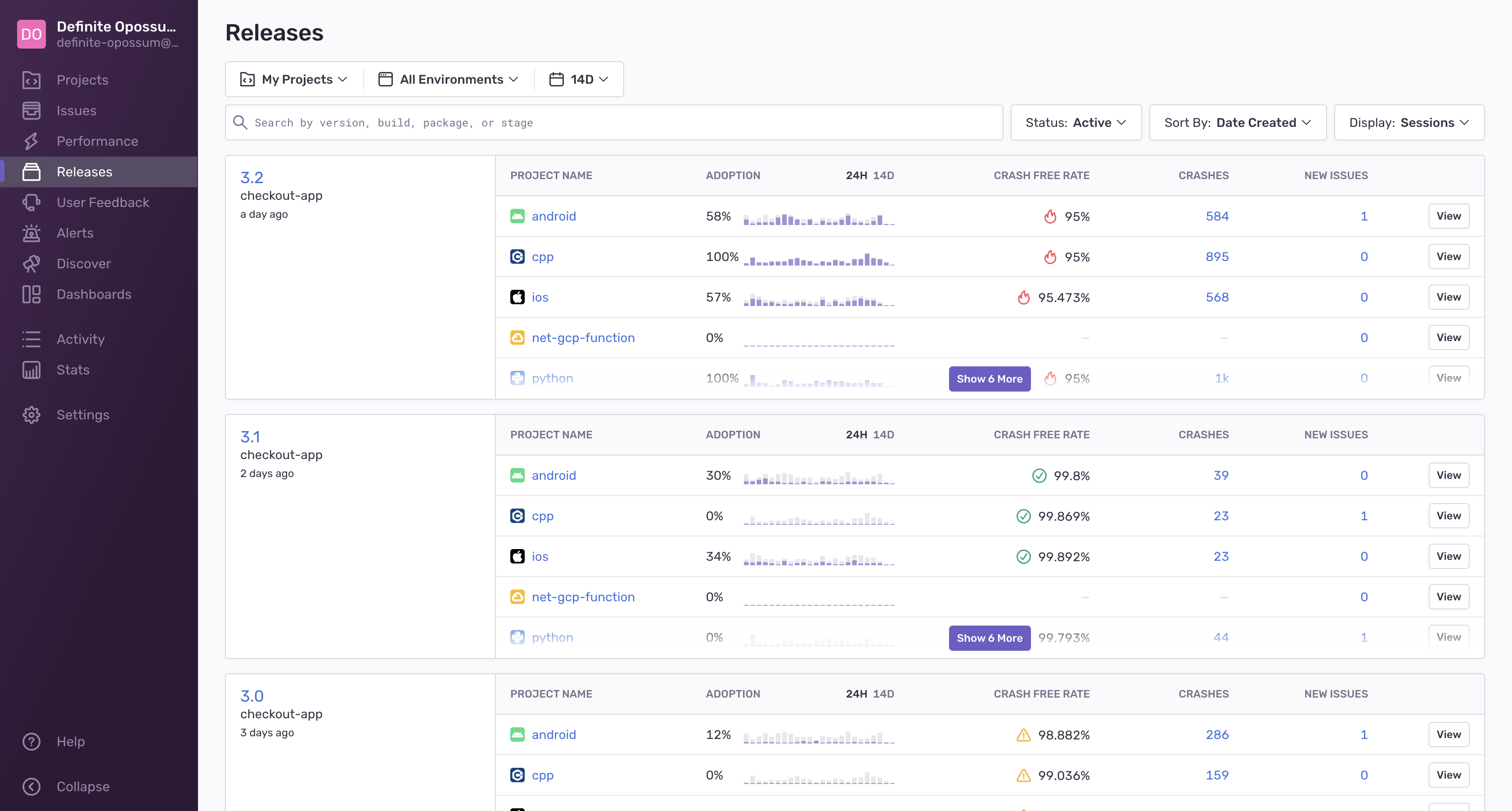
Monitoring release stability & adoption
“Sentry has been instrumental in identifying issues that happen in production, both on the frontend and the backend.”
Understanding how teams work, not just what they’re doing
Leading a team through different growth stages requires unique and evolving insights. Alex uses Sentry to understand how his teams are working – not just what they’re working on – through monthly, quarterly and annual reviews and retrospective data, identifying overarching trends by looking at issues over time. This informs leadership on whether roadmaps are working or should be adjusted.
Engineering managers do this on a more regular basis, monitoring service-level objectives like error budgets and progress towards individual KPIs. This strategy helps Alex see where teams might need help and has contributed to sustainable growth and a better developer experience.
As an early adopter of Sentry, Alex has seen how equipping your team up with the right tools from the start can be a boon to growth. That said, they expect the same level of performance and scalability from their APM tools as the products and features they build for customers.
“A lot of solutions do error monitoring, but Sentry goes the extra mile when it comes to details.”
Keen to spend more time building great experiences and less time investigating issues? Gorgias’ engineering team is growing fast and they’re looking to fill roles across disciplines, check them out.